I like to read tagesschau.de, so I wrote a script to scrape it in regular intervals.
My original goal was to determine which articles stay on the front page the longest, which ones allow commenting (a feature that seems to have been disabled almost entirely since March 2020), and if articles are modified after the initial release (without mentioning this), because I sometimes feel that headlines change.
Dataset Creation §
Tagesschau provides a JSON API, so fetching all of the articles is relatively straightforward and can be done with just a few lines of code.
now = datetime.now()
date_time = now.strftime("%Y-%m-%d_%H_%M_%S")
url = f"https://www.tagesschau.de/api2/"
r = requests.get(url)
path = join(root, f"{date_time}.json")
if r.status_code == 200:
data = r.content
with open(path, "w") as f:
f.write(data.decode())I automatically ran this script once per hour for more than two years, which gave me $\approx$ 15,000 unique news articles.
Exploratory Data Analysis §
Now that we have a dataset, we can do some exploratory data analysis. For example, we can investigate when articles are published. Let’s plot the number of articles per weekday:
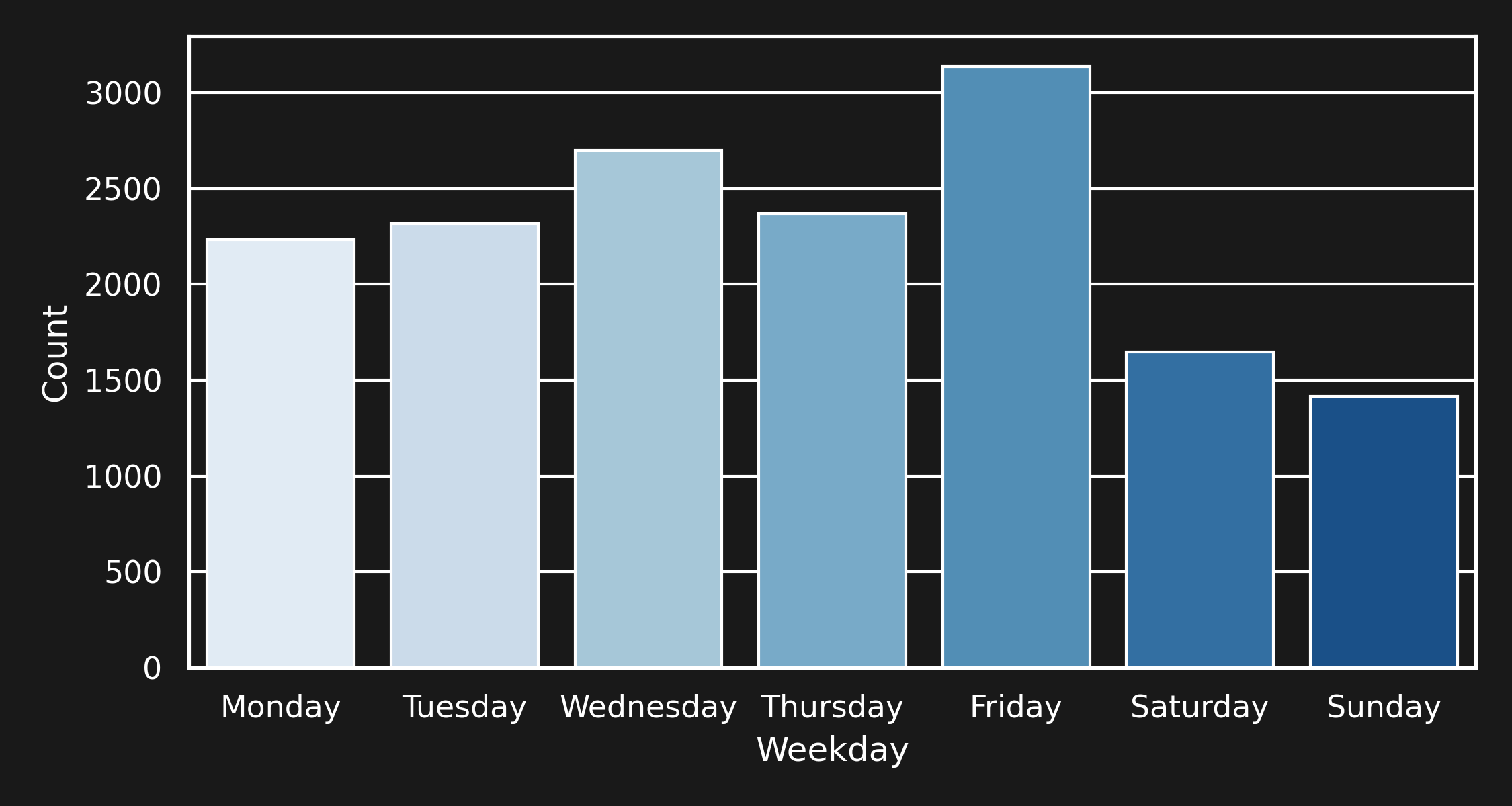
More articles are published on Wednesday and Friday, while, during the weekend, the least articles are published. This sounds reasonable: fewer people work on the weekend, so there are fewer articles. But what is the reason for the spike on Fridays? Since the articles contain the exact publication date, we can plot the distribution of articles for each day, over each hour. The plot looks like this:
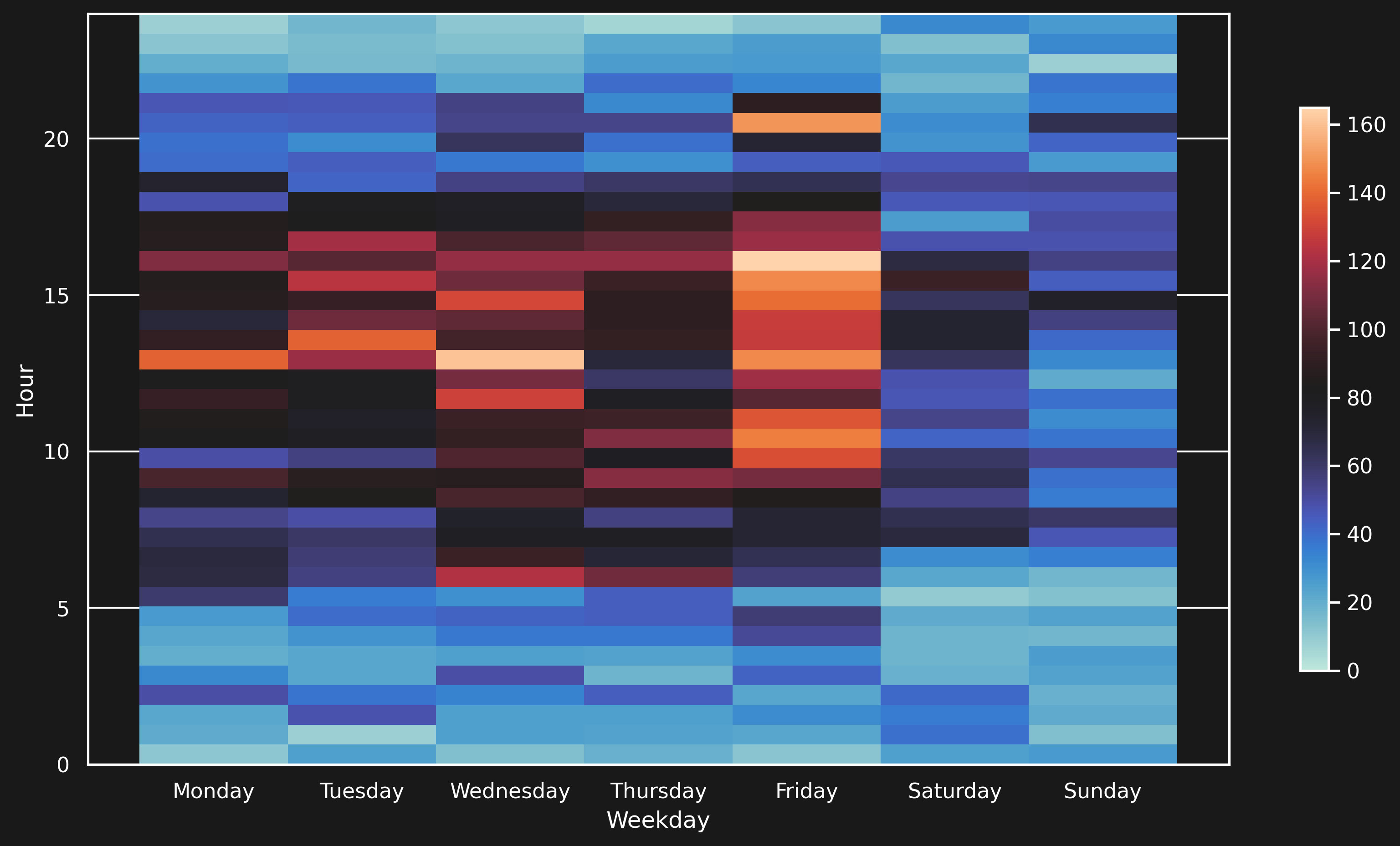
Here, we notice something interesting: Quite a lot of articles are published on Friday around 17:00 and 20:00. My hypothesis is that these are articles that the editorial staff pushed out so that people have stuff to read during the weekend.
Let’s have a look at the length of the articles:
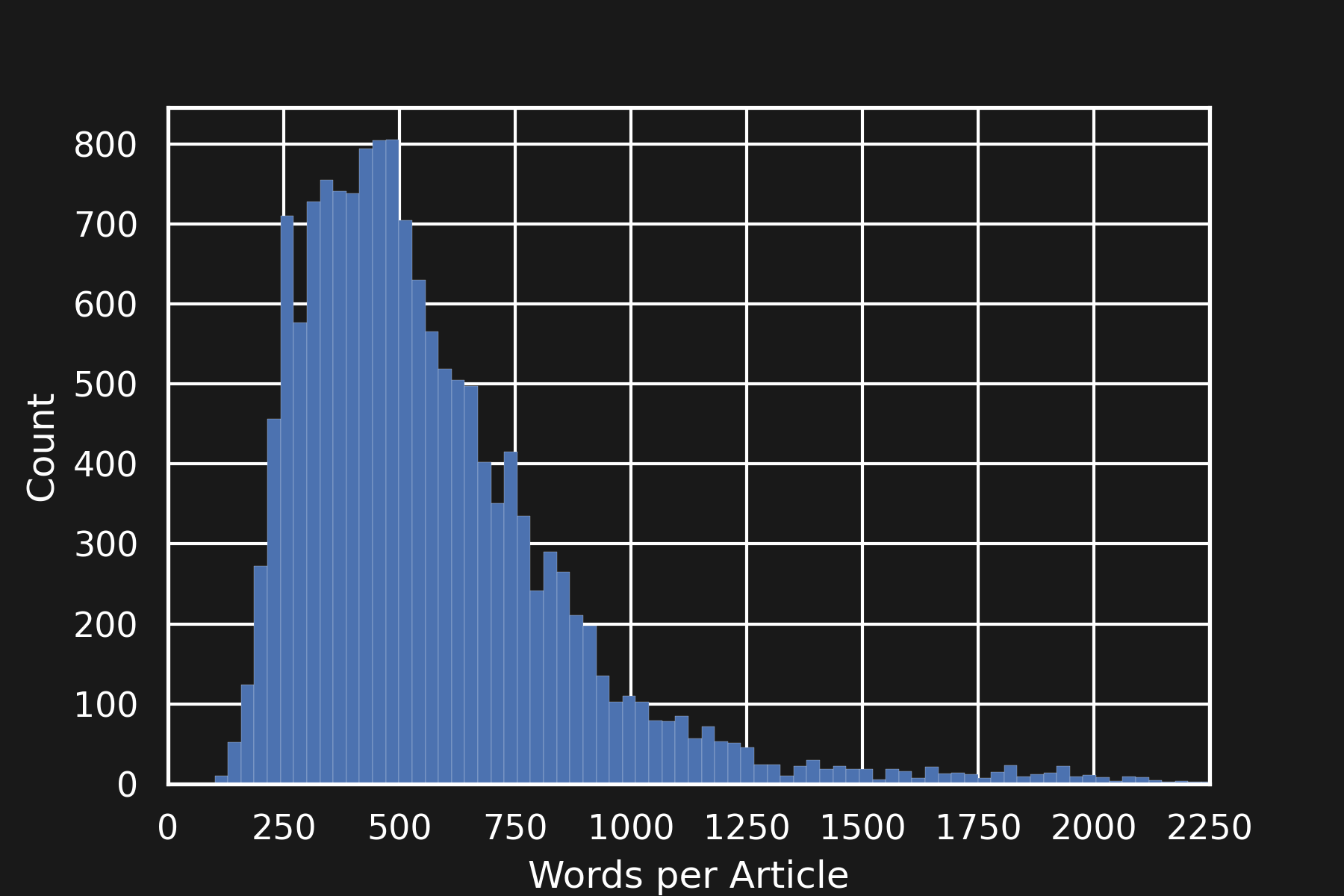
If the hypothesis is true, we could expect that the articles published on a Friday evening are longer than average. The histogram of the number of articles, plotted against the hour and the number of words in the articles looks like this:
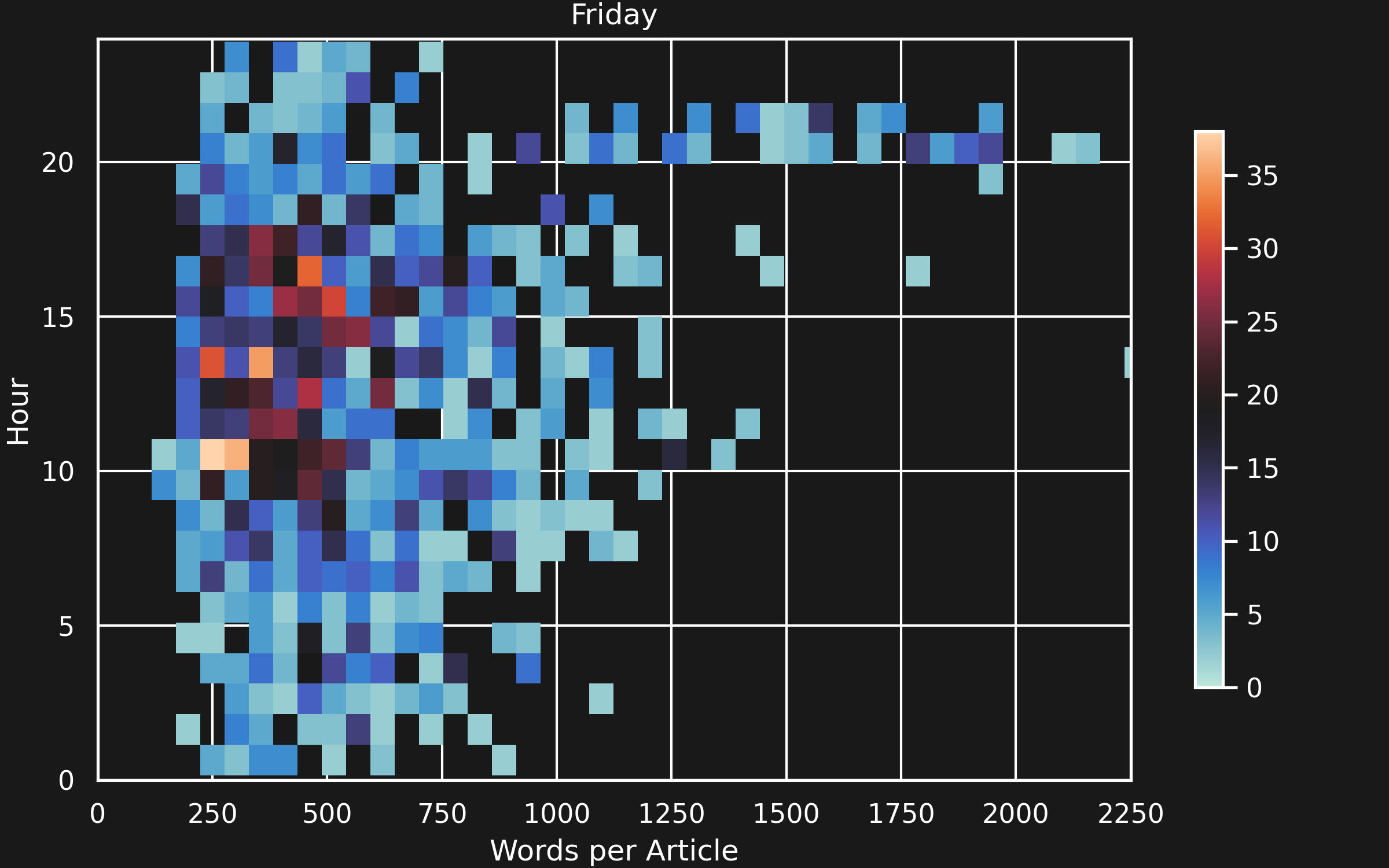
Length of articles released on Fridays, over time.
This seems to support the hypothesis: Friday evening after the tagesschau has aired, an unusual amount of lengthy articles is published. This does not seem too far-fetched.
Masked Language Modeling §
Masked language modeling can be seen as a special kind of classification task. Given the previous and the next word, what is the probability of the masked word?
Consider the sentence:
The [mask] jumps over the lazy dog.
Here, we are trying to find the most probable word for [mask]. We can then do this for every word in some dataset, and multiply the results, or, in mathematical terms
$$ p(\mathcal{D} \vert \theta) = \prod_{x \in \mathcal{D}} p(x_i | x_{j \neq i}, \theta) $$
where $\mathcal{D}$ is a dataset with a set of documents $x$,and $\theta$ are the parameters of our model.
In practice, instead of maximizing this probability during training, we will minimize its negative logarithm, which will turn the product into a sum.
This also has the benefit of being more stable, numerically.

Language modeling by recovering masked inputs.
Clustering §
We can use a model trained for masked language modeling for clustering. Below, you can find a clustering of the articles based on their content. Articles are vectorized by a German version of BERT, the visualization uses PCA and T-SNE. The color represents the category to which the articles were assigned. Using the categories as a sanity check, the clustering seems to work reasonably well. In fact, we can even find some articles that apparently have been categorized wrong.
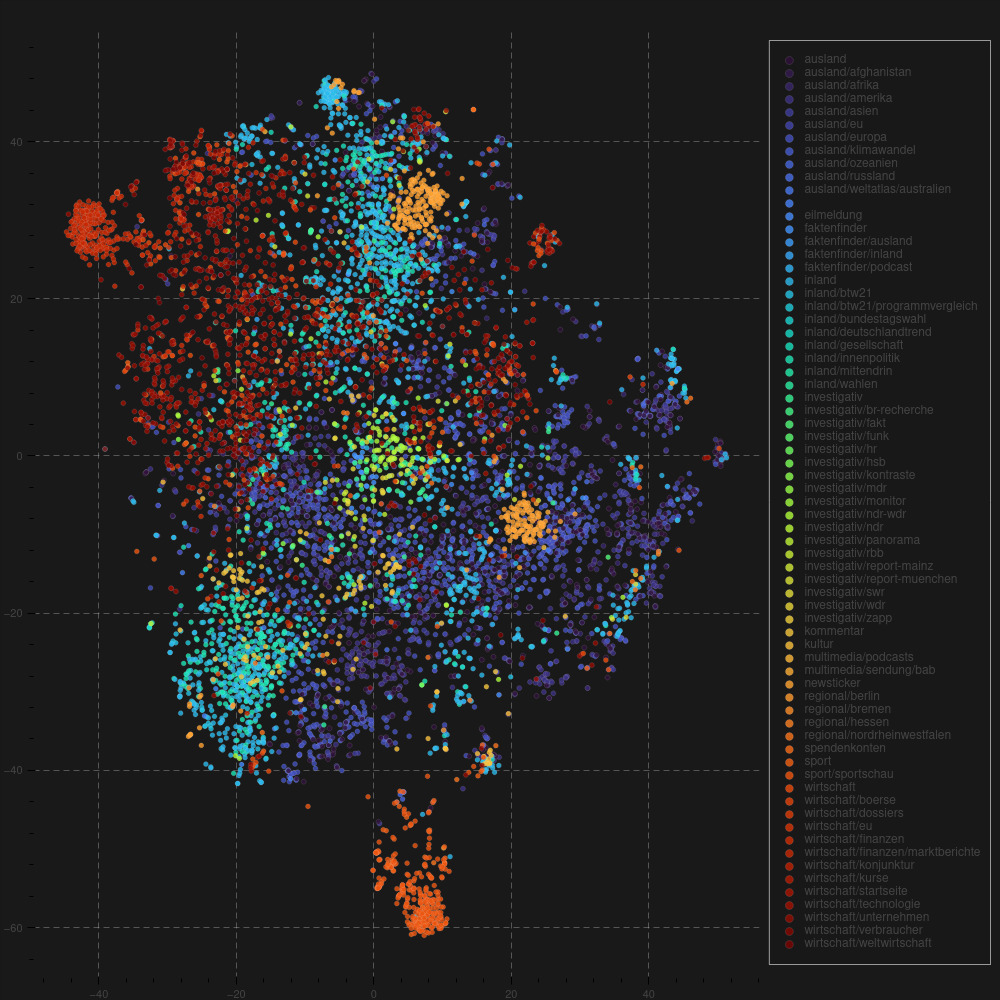
Article Clustering based on BERT
Generative Language Modeling §
We can use this dataset to create a fake news generator.

GPT General architecture
GPTagesschau §
I fine-tuned a German GPT-2-based language model on the dataset to generate news articles in the style of tagesschau.de. The model is not that good yet, which is probably due to the fact that
- German pre-trained language models are not as good as their English counterparts and
- the dataset is too small (15k unique articles at the time of writing).
Still, the generated (fake) news articles are somewhat coherent, even if they tend to contradict themselves. The model is also able to generate titles and headlines.
In the following, I give a rather funny example. Note that I did not select this article for its realism, but because I thought the apparent mixture of two topics makes it an interesting read.
Inhaftierter Wikileaks-Gründer: Erste Anklage gegen Assange?
Die US-Justiz hat in London den Prozess gegen Julian Assange eingeleitet. Ihm wird vorgeworfen, im Irak Anhänger einer Terrormiliz bekämpft zu haben. Assanges Unterstützer sollen im Krieg gegen den Irak an Waffen und Ausrüstung gekommen sein.
Ein britisches Gericht hat den Rechtsstreit um die Auslieferung des Enthüllers der Enthüllungsplattform Wikileaks, Julian Assange, in Großbritannien begonnen. Für den Gründer der Demokratie-Bewegung Assange bestehe die Chance, die Untersuchungshaft in London absitzen zu können, teilte die Londoner Generalstaatsanwältin Letitia James mit. “Assange kann hoffen, eine Chance zu haben, in einem fairen Prozess von allen Seiten an das Richtige erinnert zu werden.” Assange drohen bei einer Verurteilung bis zu 175 Jahre Haft. Die Staatsanwaltschaft wirft ihm vor, Anhänger der Terrormiliz “Islamischer Staat” (IS) und des IS-Regimes mit Waffen und Ausrüstung versorgt zu haben.

